Síťový monitoring
Síťový monitoring slouží jak ke kontrole stavu sítě, její dostupnosti, stability, bezpečnosti, průchodnosti... tak i ke sledování, zda a za jakých okolností dochází na síti k přetížení, malým problémům, crashům či kompletní nefunkčnosti sítě. Na jakýkoliv problém může program síťového monitoringu upozornit administrátora. Současně však na základě zjištěných dat může aktivovat přednastavené automatické procesy bez nutného zásahu lidského faktoru. Například u serverů poskytujících převážně obsah ke shlédnutí (typu YouTube) bude v případě přetížení aktivovat záložní přístupové cesty. U crashů, kdy software či operační systém přestane správně pracovat a ukončí se, nebo u kompletně nefunkčních serverů nebo u serverů ohrožených kyberútokem... vyřadí problémový server z provozu a současně převede komunikaci na záložní server. Dále na tuto situaci upozorní administrátora a bude čekat na pokyn, že překážka na původním serveru byla odstraněna.
Síťový monitoring zpravidla nachází uplatnění tam, kde je potřeba zabezpečit nepřetržitý a hladký provoz interní IT infrastruktury. Mohou to být buď více-méně uzavřené firemní nebo školní sítě, kde se přistupuje k citlivým datům a informacím na serveru jak pomocí pevných linek, tak wi-fi, a dále servery poskytující služby široké veřejnosti. Zde jsou typickými uživateli síťového monitoringu poskytovatelé webových nebo emailových služeb nebo třeba onlinových her, kdy je potřeba zajistit nepřetržitou přístupnost a plnou funkčnost provozu.
Pomocí síťového monitoringu se správce sítě dozví užitečná data o jejím chodu, například typických časech píkového zatížení, což mu pak dále pomůže při budoucí optimalizaci sítě. Dlouhodobým sledováním se může také zjistit, jestli je zatížení sítě standardní, nebo zda se jedná o úmyslné přetížení, popřípadě odkud toto přetížení pochází a komunikaci z této IP adresy zablokovat.
Síťový monitoring je součástí celého síťového managementu. Jednotlivé systémy různých firem se od sebe liší specifickým způsobem využití (viz níže), či různým vizuálním rozhraním, vždy však obsahují podobné základní parametry, metriky a nabízejí obdobnou analytiku a management.
Metody monitoringu
Raw traffic
Jedná se o nejejdnodušší způsob sběru dat provozu sítě. Veškeré pakety jsou uloženy ve své surové (raw) podobě. K další analýze se může použít DPI.
Nástroje pro Deep packet inspection (DPI) poskytují 100% přehled o síti tím, že transformují nezpracovaná data do čitelného formátu a umožňují správcům sítě a zabezpečení proniknout do nejmenších detailů.
NetFlow
NetFlow je systém síťových protokolů vytvořený společností Cisco, který shromažďuje data o síťovém provozu, který proudí z jednotlivých rozhraní a do nich. Data NetFlow jsou následně analyzována a vytvářejí obraz o toku(flow) a objemu síťového(net) provozu - odtud název NetFlow.
Metadata
Tato metoda představuje zlatý střed mezi ostatními deep packet inspection a NetFlow. Data paketů jsou shromažďována softwarem, kde jsou tříděna, analyzována a indexována. To umožňuje vytvářet a dlouhodobě uchovávat grafy a statistiky o síťovém provozu, využití, šířce pásma, a dokonce i o výkonu aplikací. Bohužel je uchováno méně dat než při použití DPI.
Metody monitoringu
Hardware tap
Nejjednodušší řešení síťového monitoringu je hardwarový tap, jedná se o zařízení, které zrcadlí veškerý provoz na síti na monitorovací zařízení. Můžeme si ho představit jako hub který, nepotřebuje žádnou elektřinu k fungování. Hardware tap může být jak na bázi měděných vodičů, tak na optických vláknech.
Software řešení
Pokročilým metodou monitorování sítě je softwarové odposlouchávání komunikace. Tento typ odposlechu je často nejlevnější na implementaci, ale vyžaduje složitější konfiguraci, aby poskytl skutečně kompletní pohled na síť.
Pro implementaci můžete použít software jako například Suricata, SolarWinds nebo Nagios.
Port mirroring
Další metodou monitorování sítí je zrcadlení portů (u výrobců, jako je Cisco, se nazývá "SPAN" (Switched Port Analyzer). Switch port Analyzer je efektivní, vysoce výkonný systém pro monitorování provozu. Duplikuje síťový provoz na jedno nebo více monitorovacích rozhraní při průchodu switchem.
Metriky
Dostupnost
První, nejelementárnější metrika. Udává, zda-li je služba/server momentálně dostupný. Například, zda se dá přistoupit k webové stránce, připojit se na herní server nebo stáhnout soubor z FTP serveru.
Uptime
Jedná se o základní metriku ukazující na spolehlivost a stabilitu systému. Je udávána v procentech; typicky kolik procent z celkového sledovaného času systém fungoval a byl dostupný. Pozor: v některých systémech síťového monitoringu se ale může jednat o dobu, po kterou systém pracoval bez restartu.
Response time
V češtině čas potřebný k vyřízení žádosti. Je to součet časů, kdy Vyřízení žádosti = čas čekání ve frontě požadavků + čas zpracování žádosti + čas vrácení odpovědi. Zpravidla je udáván v milisekundách.
Pozor: s lineárně se zvedajícím zatížením se nelineárně zvedá response time. Pokud se zařízení blíží ke svému 100% zatížení, tak se velice dramaticky zvedá čas odpovědi z důvodu dlouhého čekání ve frontě požadavků.
S tímto termínem se můžeme setkat v široké škále služeb.Typicky jde například o délku trvání vyřízení SQL dotazu na databázi nebo načtení webové stránky.
Round trip delay (RTD)
Je doba, za jakou je požadavek poslán a přijat zpátky. Je udáván v milisekundách. Také jej můžeme označit jako jako „ping time“. Pro jeho zjištění se používá programu ping a protokolu ICMP.
Ping nám taky vypíše procenta ztráty packetů, což může být užitečné při zkoumání problémové služby nebo serveru a také vypíše minimální RTD, maximální RTD a průměrný RTD.
Příklad:
C:\WINDOWS\system32>ping 1.1.1.1
Pinging 1.1.1.1 with 32 bytes of data:
Reply from 1.1.1.1: bytes=32 time=12ms TTL=57
Reply from 1.1.1.1: bytes=32 time=15ms TTL=57
Reply from 1.1.1.1: bytes=32 time=10ms TTL=57
Reply from 1.1.1.1: bytes=32 time=28ms TTL=57
Ping statistics for 1.1.1.1:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 10ms, Maximum = 28ms, Average = 16ms
End-to-end delay (OWD)
Nebo také One-Way Delay je čas, který trvá packetu od odeslání požadavku k jeho přijetí druhým zařízením. Je udáván v milisekundách. Jako hrubý odhad se dá použít polovina času RTD, ale pro přesnější měření je lepší měřit RTD přímo. Je nutné měřit ho synchronizovanými hodinami... Server A odešle packet s přesnou dobou odeslání, server B ho přijme a zaznamená čas přijetí. Rozdíl obou časů je end-to-end delay. Pozor: přesnost přímého měření závisí na dokonalé synchronizaci hodin serverů.
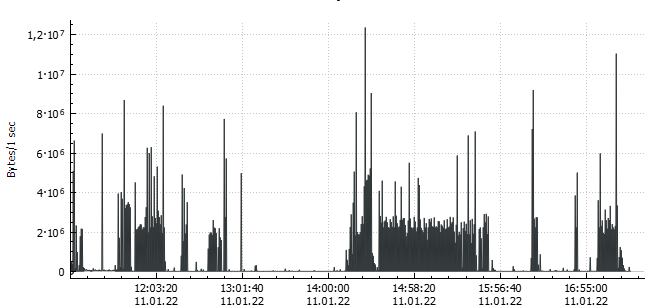
Network traffic measurement
Je měření síťového provozu. Měří se 1) množství komunikace a 2) její typ. Vizuálním výstupem je zpravidla přehledný graf zobrazující zatížené sítě přijímáním a odesíláním požadavků na časové ose. Správně změřený Network traffic measurement je důležitým nástrojem pro optimalizaci síťového provozu - pro efektivní Bandwidth management.
Bandwidth management
Je důležitý prvek pro udržení zdravé sítě. Jedná se o řízení komunikace, aby se zabránilo naplnění kapacity nebo přetížení sítě. Ze široké škály technik a mechanismů Bandwith managementu vybírám tyto tři.
Traffic shaping
Nebo také Rate limiting směřuje k rovnoměrnému využití sítě ořezáním špiček = zpožděním určitých paketů od určitých uživatelů sítě, tak, aby se zprůměroval Response time pro všechny návštěvníky. Pokud určití uživatelé přetěžují síť, jsou jejich pakety zpožděny, aby uživatelé s vysokou latencí (dolní píky) měli lepší Response time. Obecně: Traffic shaping slouží k optimalizaci výkonu sítě a zlepšení latence.
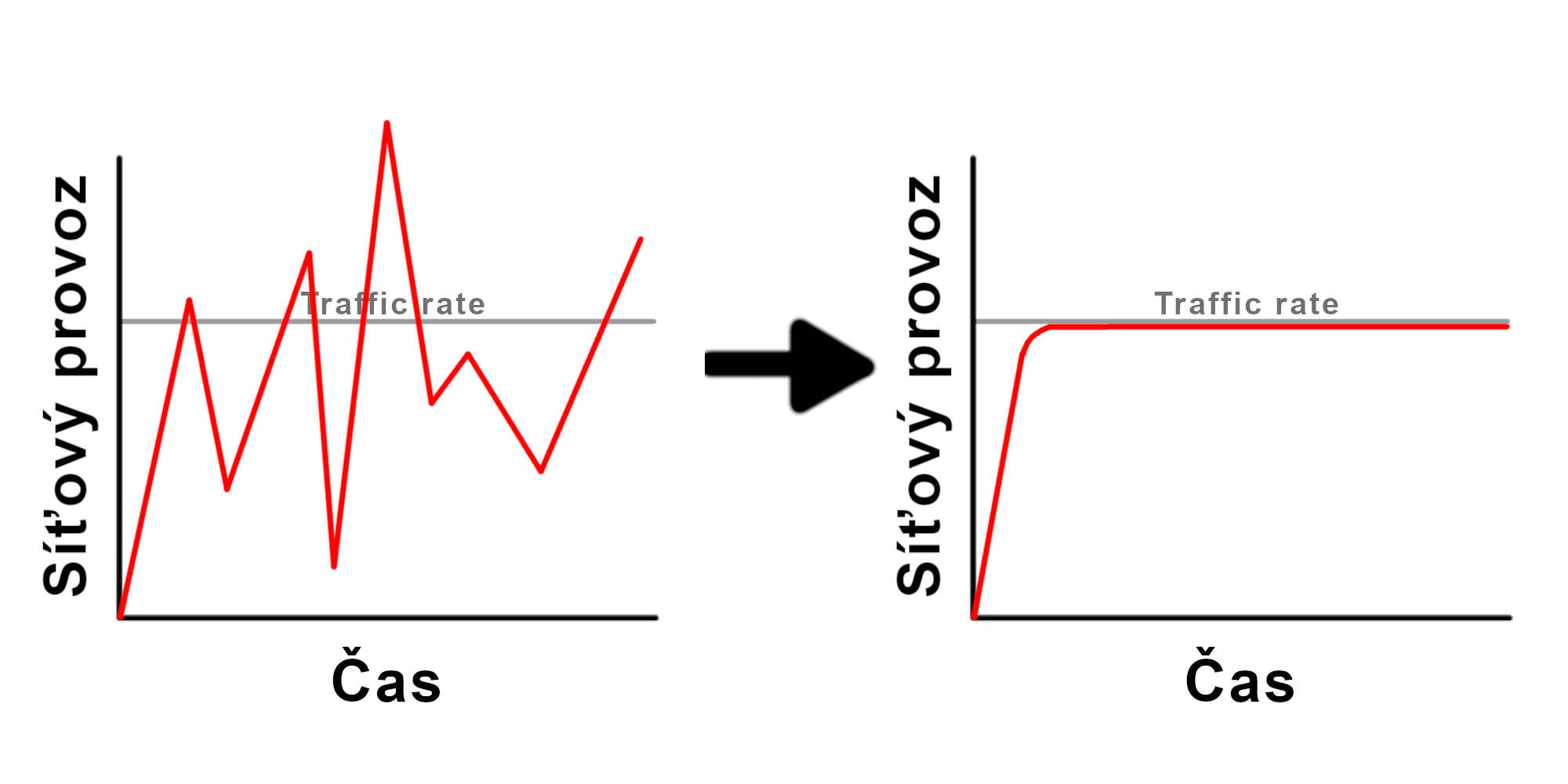
Může se jím také zabránit DoS (Denial of Service) útokům nebo web scrapování. Pokud program síťového monitoringu vyhodnotí příliš vysoké množství požadavků z jednoho místa jako web scrapping, může automatické nastavení sítě vrátit tomuto uživateli Error 429: Too many requests.
Network scheduler (Algoritmus řazení do fronty)
Řídí pořadí síťových packetů ve vysílacích a přijímacích frontách. Nejjednodušší algoritmus pro pochopení je First in First out (FIFO), kde se všechny požadavky řeší v tom pořadí, v jakém přišly. Z důvodů různých prioritizací a zrovnoměrnění provozu na síti se ale v současnosti využívá přes 25 různých algoritmů pro řazení packetů do fronty.
Resource reservation protocol (RSVP)
Je prostředek, kterým aplikace sdělují své požadavky na rezervování prostředků podél trasy v end-to-end přenosu cestou přes síť. Pokud si každé síťové zařízení na trase může rezervovat potřebné prostředky, původní aplikace může začít vysílat.
Pokud je Bandwith Management již zoptimalizovaný, můžeme se na svou síť podívat jinak, pomocí Network Tomography a Route Analytics.
Network tomography
Slouží pro vizuální zobrazení topologie sítě z dat z jejích koncových bodů. Takže i když nemáme žádné informace o síti, můžeme mít perfektní přehled o její topologii, zařízeních a síťových linkách.
Route analytics
Zahrnuje metody, systémy, algoritmy a nástroje pro monitorování a analýzu routovacích protokolů v sítích. Nesprávné routování nebo problémy s routováním způsobují nežádoucí snížení výkonu nebo v nejhorších případech výpadky.
Upozornění administrátorovi
Když automatická řešení problémů nejsou dostatečná, a síťový monitorovací systém vyhodnotí situaci jako nestandardní anomálii, je potřeba okamžitý zásah správce sítě. V těchto případech je administrátor upozorněn například sms zprávou, kterou mu zašle monitorovací software a vyzve ho k okamžité akci. Rychlý zásah člověka je klíčový v případě nutnosti akutních řešení nestandardních situací, kdy u velkých firem může výpadek interní sítě způsobit ztráty vysokých částek už po pár hodinách výpadku. U některých činností, například v řízení letového provozu výpadek služby vůbec nepřipadá v úvahu. Převádí se na záložní servery a administrátor musí rychle najít řešení a převést systém opět na základní a záložní.
Příklad upozornění:
Notification Type: PROBLEM
Host: dbserver1
State: DOWN
Address: 70.85.16.87
Info: CRITICAL - Host Unreachable (70.85.16.87)
Date/Time: 10.1 03:25:45 2022
Příklady monitorovacího softwaru
SolarWinds
Je industriálním standardem pro síťový monitoring. Využívá simple network management protokolu (SNMP). Ten slouží pro sbírání dat o chodu sítě. Dokáže vše co bychom od softwaru pro monitorování sítě chtěli. Například monitorovat a zobrazovat všechny metriky, troubleshooting sítě, dynamické mapování bezdrátových zařízení a mnoha dalších.
Nagios
Nagios je open-source alternativa SolarWinds. Nagios nabízí služby monitorování sítě a umí generovat všechny metriky popsané v této kapitole. Dále upozorňuje administrátora, když se něco pokazí, a podruhé ho upozorní, když se problém vyřeší. Nagios, ale také umí monitorovat hardware serverů jako například teplotu různých komponent a tato data analyzovat.
Nmap
Je užitečný při zjišťování informací o neznámé síti. Například když se někdo snaží opravit nebo jenom porozumět síti, kterou nezná. Může se jednat o případ, kdy předchozí admin již nepracuje v dané firmě a detailní informace o nastavení sítě odešly spolu s ním, nebo pokud jsme přivoláni někam kde síť nefunguje a administrátor, který síť spravuje si s řešením neví rady. Jak funguje Nmap je podrobně popsáno v předchozí kapitole “Nmap”
Wireshark
Při monitorování sítě slouží k zobrazení packetů mezi zařízením a destinací, takže se monitoruje čistě komunikace mezi těmito dvěma body. Také je užitečné filtrování komunikace, tím se můžeme soustředit na jednu specifickou věc, nebo naopak na širší škálu věcí. Wireshark je podrobně popsán v předchozí kapitole “Wireshark”
IDS
Intrusion detection system je prvek kontrolující veškerou komunikaci na síti a detekující podezřelé chování. Například může rozpoznat arp-spoofing, dhcp starvation, ddos a mnoho dalších útoků. Komunikaci však nekontroluje přímo, ale je umístěn mimo hlavní cesty, aby nijak neovlivňoval rychlost přenosu dat na síti.
IPS
Intrusion prevention system je nástavba na IDS. Na rozdíl od IDS je ale posazen přímo za firewall na přímou komunikaci, kterou analyzuje. To znamená, že musí pracovat velice efektivně, aby nijak zásadně nezpomaloval chod sítě.
Pokud detekuje nějaké podezřelé chování, tak informuje administrátora (stejně jako IDS), ale může navíc provádět předem definované automatizované opatření jako například: dropnout nebezpečné packety nebo zablokovat veškerou komunikaci od zdrojové ip adresy a pod.